Новости НКРЯ
Национальному корпусу русского языка – 20 лет!
29 апреля 2004 года сайт Корпуса был открыт для свободного доступа. Но работы по созданию НКРЯ начались значительно раньше, еще в 2000 году. Символично, что официальным «днем рождения» Корпуса стало именно 29 апреля – день рождения российского лингвиста, автора Грамматического словаря русского языка А. А. Зализняка (1935-2017).
Всё началось с идеи создать полное собрание текстов, которые были бы показательными с культурной точки зрения и отражали бы разнообразие прозы, написанной в период с 1965 по 2000 год. Сейчас НКРЯ – это 49 корпусов общим объемом более двух миллиардов слов. За 20 лет Корпус стал незаменимым инструментом для лингвистов, преподавателей, студентов и всех, кто интересуется русским языком.
Поздравляем создателей проекта и тех, кто помогает ему развиваться! Благодаря вам НКРЯ продолжает расти и совершенствоваться, предоставляя новые возможности для изучения русского языка.
Для тех, кому интересно узнать больше об истории и современных возможностях Корпуса, мы подготовили подборку материалов:
- Посмотрите, как выглядел сайт Корпуса 20 лет назад, в Музее НКРЯ.
- Погрузитесь в историю создания Корпуса «из первых уст» в специальном проекте «Большого города».
- Ознакомьтесь с Руководством пользователя и узнайте, как использовать корпус для разных задач.
- Изучите публикации о Корпусе в недавно обновленном разделе. Рекомендуем обратить внимание на свежую публикацию в журнале «Вопросы языкознания» о фундаментальной реконструкции и модернизации платформы НКРЯ.
- Скачайте и примените для собственных задач нейросетевые модели, которые используются для разметки слов и текстов Корпуса.
- Узнайте, как получить офлайновую версию Корпуса для исследований.
Тех, кто хочет принимать участие в развитии корпуса, приглашаем вступить в группу «Друзья НейроКРЯ». Вы будете первыми узнавать о готовящихся проектах и сможете принимать в них участие. Недавно мы запустили новый эксперимент, чтобы выяснить, какие определения слов лучше воспринимаются пользователями: взятые из словарей или сгенерированные нейросетью.

На сайте Национального корпуса русского языка появился новый раздел, посвящённый нейросетевым моделям, которые используются для разметки слов и текстов Корпуса.
Теперь пользователям доступны:
- токенизатор
- векторные word2vec модели, обученные на текстах из 7 корпусов, которые мы используем для поиска слов-ассоциатов
- модели для словообразовательной разметки
- модели для разметки тематики, жанров, типов текстов
Новый раздел будет полезен всем, кто интересуется обработкой естественного языка и хочет узнать больше о том, какие технологии машинного обучения применяются в НКРЯ. Пользователи могут ознакомиться с описанием моделей и скачать их для собственного использования. Перед скачиванием модели надо ознакомиться с лицензионным соглашением и принять его условия.
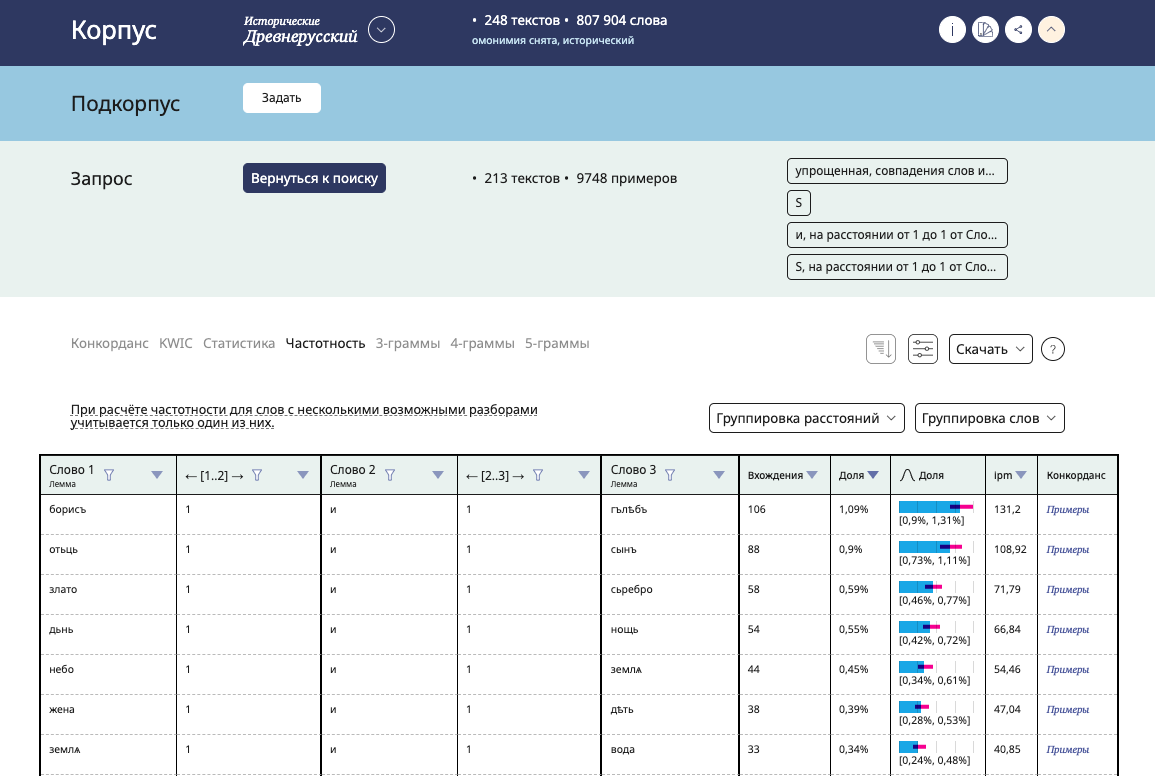
В апреле мы значительно усовершенствовали работу Древнерусского корпуса. В корпусе появились новые виды выдачи: Частотность, Статистика, n-граммы. Благодаря появлению в Древнерусском корпусе вида выдачи «Частотность» можно исследовать, например, какие существительные в корпусе чаще всего встречаются вместе. Кроме того, результаты выдачи теперь можно сортировать по контексту. В портрете корпуса появился Частотный словарь, доступный ранее в Основном, Газетном и других корпусах; частотный словарь памятников или их групп можно сравнивать со словарем корпуса текстов.
Появление нового функционала существенно расширяет возможности использования корпуса и автоматизирует рутинные процессы, которые ранее занимали у исследователя значительное время.

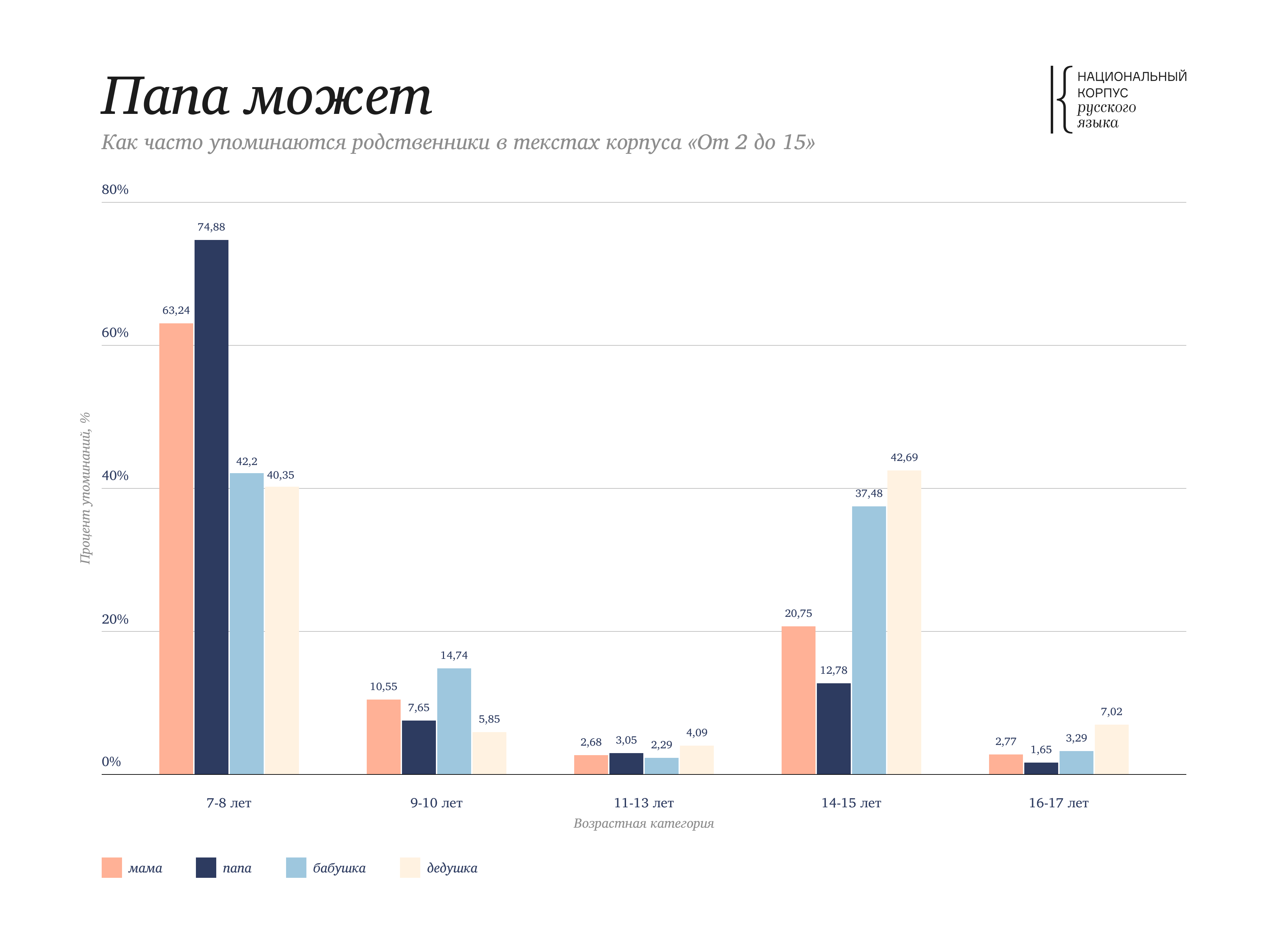
Мы продолжаем внедрять новый функционал, уже доступный в передовых корпусах — Основном, Газетных, Обучающем — в другие корпуса. Теперь пользователям НКРЯ доступна улучшенная версия корпуса «От 2 до 15». Во всех текстах корпуса автоматически снята грамматическая омонимия и добавлена разметка синтаксических связей. В корпусе стали доступны поиск по синтаксическим отношениям и поиск коллокаций, а также новые виды выдачи: частотность, н-граммы, статистика.
Обновились портрет слова и корпуса, добавлены новые виды сортировок по контексту.
В Портрете слова можно увидеть, что слова мама и папа гораздо чаще употребляются в текстах для самых младших читателей - 7-8 лет, а слова бабушка и дедушка - поровну в текстах для самых младших читателей и для подростков 14-15 лет.
Плашка возле фрагмента с указанием возраста читателей, которым эти фрагменты должны быть понятны, стала кликабельной. По клику вы увидите рассчитанные классические индексы сложности: Индекс Флеша-Кинкейда, Индекс Колман-Лиау, Автоматический индекс удобочитаемости, Simple Measure of Gobbledygook, Индекс Дейла-Чалл.

В преддверии 20-летия Национального корпуса мы существенно обновили страницу публикаций на нашем сайте. Пополнен список публикаций о Корпусе: количество публикаций увеличилось примерно в 5 раз! Теперь в разделе представлены как научные статьи, так и другие типы публикаций — интервью, инструкции, публикации в социальных сетях.
Страница публикаций о Корпусе стала более функциональной: теперь найти публикацию, посвященную Национальному корпусу русского языка, можно в строке поиска или с помощью фильтров, расположенных справа.
По умолчанию пользователю показываются наиболее популярные фильтры. Чтобы увидеть все доступные фильтры на странице публикаций, нажмите «Показать все». Сочетание нескольких фильтров сужает поиск и позволяет отобрать публикации по нескольким критериям.
Некоторые публикации можно скачать, нажав на иконку справа от названия. Остальные публикации открываются в отдельном окне. Вы можете поделиться списком отобранных публикаций, нажав на кнопку «Копировать ссылку на запрос».
На сайте НКРЯ доступны два новых параллельных корпуса. Японско-русская языковая пара насчитывает более 400 тысяч слов и включает переведенные с японского художественные тексты и новости. Хакасско-русские параллельные тексты, подготовленные для НКРЯ на базе Электронного корпуса хакасского языка, насчитывают более 1 млн словоупотреблений и охватывают и фольклор (включая записи XIX в.), и авторскую литературу, и публицистику.
Пополнены и уже имеющиеся параллельные корпуса. Существеннее всего выросли португальский (теперь 1.6 млн словоупотреблений) и чешский (4.3 млн) корпуса.
В Портретах слова Газетного, Обучающего корпуса и корпуса «Русская классика» появились новые виджеты.
В корпусе Центральных СМИ и корпусе «Русская классика» появились виджеты Скетчи, Частотность слова и Похожие слова. Поскольку портрет слова строится на материале корпуса, то скетчи и похожие слова для одного и того же слова получаются разными в разных корпусах. Например, в текстах корпуса Центральных СМИ шутка чаще всего бывает злой и первоапрельской, а в произведениях русских классиков — колкой и забавной.
Обновился виджет Статистика во всех трех корпусах. Переходите по ссылке, чтобы узнать, в каком типе текстов русских классиков чаще употребляется слово анекдот.
В марте была существенно улучшена работа Синтаксического корпуса. В СинТагРусе появились новые типы информации и поисковые поля. Начиная со Слова 2, можно задать кореферентную и темпоральную связь. В поле Дополнительные признаки теперь есть возможность искать эллидированные слова, т. е. такие слова, которые опущены (подвергнуты эллипсису) в предложении, но присутствуют в его синтаксической структуре.
Поиск по микросинтаксической разметке позволяет идентифицировать устойчивые выражения разных типов. Например, отобрав конструкции все равно 1, все равно 2 и все равно 3 пользователь может увидеть особенности значения этого многозначного оборота (‘по-любому’, ‘безразлично’ и ‘эквивалентно’, соответственно) и особенности его употребления (например, все равно 2 и 3 выступают в функции сказуемого, а все равно 1 — нет).
В выдаче теперь доступна сортировка по дате создания, дате рождения автора, дате разметки и случайная сортировка. По умолчанию результаты сортируются по дате разметки текстов.
В меню синтаксических отношений, лексических функций и морфологических признаков появились подсказки. По клику на кнопку (?) в соседнем окне откроется соответствующее описание в Руководстве пользователя.
В корпусе «Русская классика» внедрена автоматическая разметка при помощи нейросетевых механизмов. Теперь в нем доступны те же поисковые и статистические инструменты, что в Основном, Газетном и других «передовых» корпусах: частотность, н-граммы, статистика по метапризнакам, скетчи в портрете слова, поиск по синтаксическим отношениям, сравнение подкорпусов по частотным словникам и многое другое. Кроме того, корпус «Русская классика» — единственный из корпусов НКРЯ, где репрезентативно представлены и стих, и письменная проза, и можно отбирать эти типы текста отдельно. Благодаря всему этому мы можем сравнить, о чем писали русские классики. Например, можно говорить о «человекоцентричности» русской классической литературы (см. иллюстрацию), а также заметить, что о душе поэты (В. А. Жуковский, Е. А. Баратынский, М. Ю. Лермонтов), писали значительно чаще, чем прозаики (А. Н. Радищев, Н. В. Гоголь, И. С. Тургенев).


В Синтаксическом корпусе появилась возможность отбора подкорпуса по основным параметрам, таким как автор, название текста, дата его создания и год рождения автора, а также по жанрам и типам текстов и по дате разметки.
Следите за нашими новостями на сайте и в социальных сетях, в марте мы продолжим совершенствовать работу Синтаксического корпуса!
